Rethinking Code Efficiency: Big O Notation, Sustainability, and the Path Forward

During my time at university, I wrestled with the concept of Big O notation, never quite grasping its real-world significance. However, when I entered the IT industry, I seldom found myself in situations where understanding Big O notation was essential.
The promise of a infinitely scalable cloud seemed to push the importance of software complexity ever more into the recesses of awareness. How many situation arose where the discussion ended with “throw more resources at it” or “compute is cheap, engineering time is expensive”. This approach has led to the creation of overly complex systems with resource footprints that frequently overshadow the significance of the software they support.
This mindset while great for cloud providers’ bottom line has reached a point where we are negatively affecting the planet we live on, and it’s time to go back to foundationals.
What is Big O Notation?
Essentially Big O notation is a way for us to estimate the time and space complexity of software (Yes big words).
To simplify this, it’s a way of roughly knowing how much compute resources a given bit of code will use as it scales with usage.
Now let’s look at two examples of sorting an array. I will be using Golang to use the benchmarking tooling.
First let’s start with a notoriously “expensive” algorithm, Bubble Sort:
func BubbleSort(arr[] int)[]int {
// First Loop Over the Array
for i:=0; i< len(arr)-1; i++ {
// Second Loop Over the Array
for j:=0; j < len(arr)-i-1; j++ {
if (arr[j] > arr[j+1]) {
arr[j], arr[j+1] = arr[j+1], arr[j]
}
}
}
return arr
}
This sort method has a “potential” complexity of O(n²). What this means is that in the worst-case scenario where the array is completely unsorted, you will need to iterate through the array once for each item in the array to have it fully sorted in order. As the array gets bigger, it will computationally take more resources to sort the array.
When comparing this to a slightly less “greedy” algorithm like Merge Sort
func MergeSort(arr []int) []int {
if len(arr) <= 1 {
return arr
}
// split the array in two
// recursively and merge them
// in order
mid := len(arr) / 2
left := MergeSort(arr[:mid])
right := MergeSort(arr[mid:])
return Merge(left, right)
}
func Merge(left, right []int) []int {
result := make([]int, 0, len(left)+len(right))
i, j := 0, 0
for i < len(left) && j < len(right) {
if left[i] < right[j] {
result = append(result, left[i])
i++
} else {
result = append(result, right[j])
j++
}
}
result = append(result, left[i:]...)
result = append(result, right[j:]...)
return result
}
We see that while this sorting method looks a lot more complicated, it actually gives a complexity of O(nlog n), meaning that as the array to be sorted grows, the resources to sort the array will grow at a vastly slower rate.
The following shows the average difference in operations running the two functions with the same list
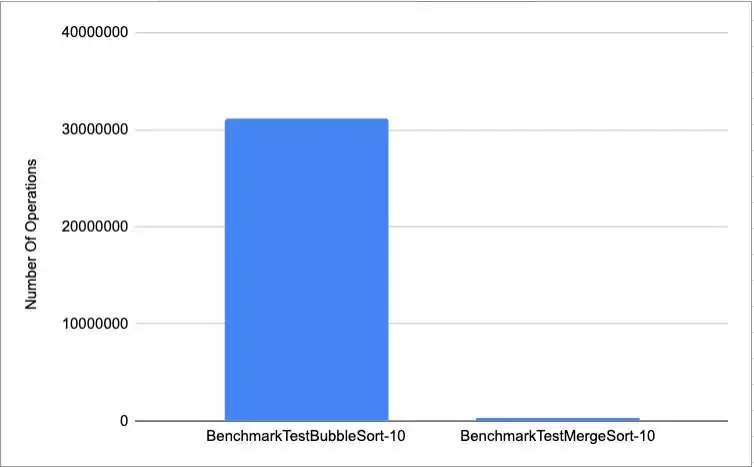
code for the above graph can be found here
An important aspect to consider when comparing the two approaches seen above is the difference in complexity. On one side, we have a relatively straightforward function that can be easily maintained and understood, on the other we have an excessively complex function that will take some time to figure out and over time will be a lot harder to maintain (keeping in mind this is a very simplified use case and is used to explain the concept), however the efficient algorithm does less operations, which in turn allows the CPU to be freed up for other processes to use it.
How does this relate to sustainability?
The undeniable truth is that, in many cases, crafting high-performance code entails introducing complexity. Complexity generally means “hard to maintain”. However, the inverse of this scenario is that non performant code will have a higher resource usage, which will then have a higher impact on emissions used. This is not necessarily a 1–1 relationship, as if we think of how software is currently run (containerized, kubernetes, etc) writing non performant code generally means allocating more nodes to a cluster to handle the needs generated by the software.
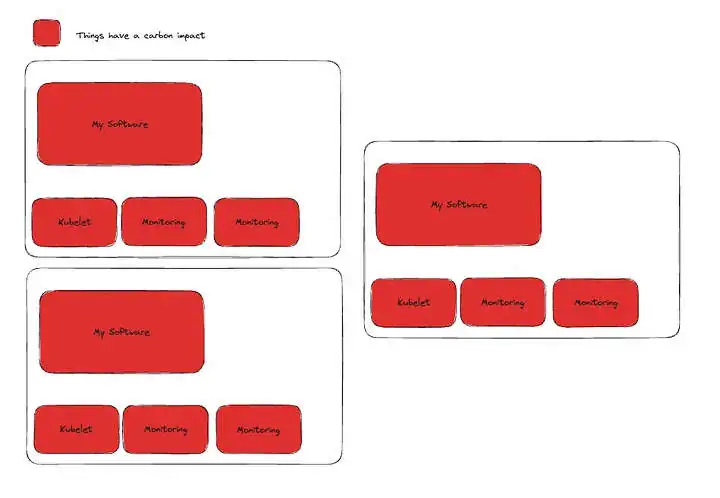
Consequently, this results in additional overhead, as for each node, we must run our monitoring stacks, kubelets, networking stack, etc. Essentially each node added to your cluster makes your software exponentially less environmentally efficient
The Path Forward
The days of infinitely scaling clouds should be seen as the naive excitement of a new technology. While there is always the argument for simplicity (which I whole heartedly agree with in most cases), the resource impact of our code should start becoming a feature in our conversations of scale. Tooling such as profilers and monitoring should be common place and better utilised to reduce our code footprint (and yes you will even be saving money).
It’s time to embrace the challenge of writing cleaner, more resource-efficient code, without sacrificing scalability or maintainability. Each GB of Memory or Core of CPU added should be a clear signal telling us that we can code better