The Evolving Landscape of Large Language Model (LLM) Architectures
The field of natural language processing (NLP) has witnessed tremendous progress in recent years, driven by the emergence of large language models (LLMs). These models have revolutionized the way we approach NLP tasks, from language translation and text summarization to question answering and text generation. In this blog post, we’ll explore the evolving landscape of LLM architectures, their history and current trends.
A Brief History of LLM Architectures
The first LLMs were introduced in the early 2010s, with the development of neural language models like recurrent neural networks (RNNs) and long short-term memory (LSTM) networks. These models were designed to learn the patterns and structures of language, using a combination of word embeddings and neural network architectures.
In the mid-2010s, the introduction of transformer models marked a significant milestone in the evolution of LLM architectures. The transformer model, introduced in the paper “Attention is All You Need” 1 , used self-attention mechanisms to allow the model to attend to different parts of the input sequence simultaneously, rather than relying on recurrent connections.
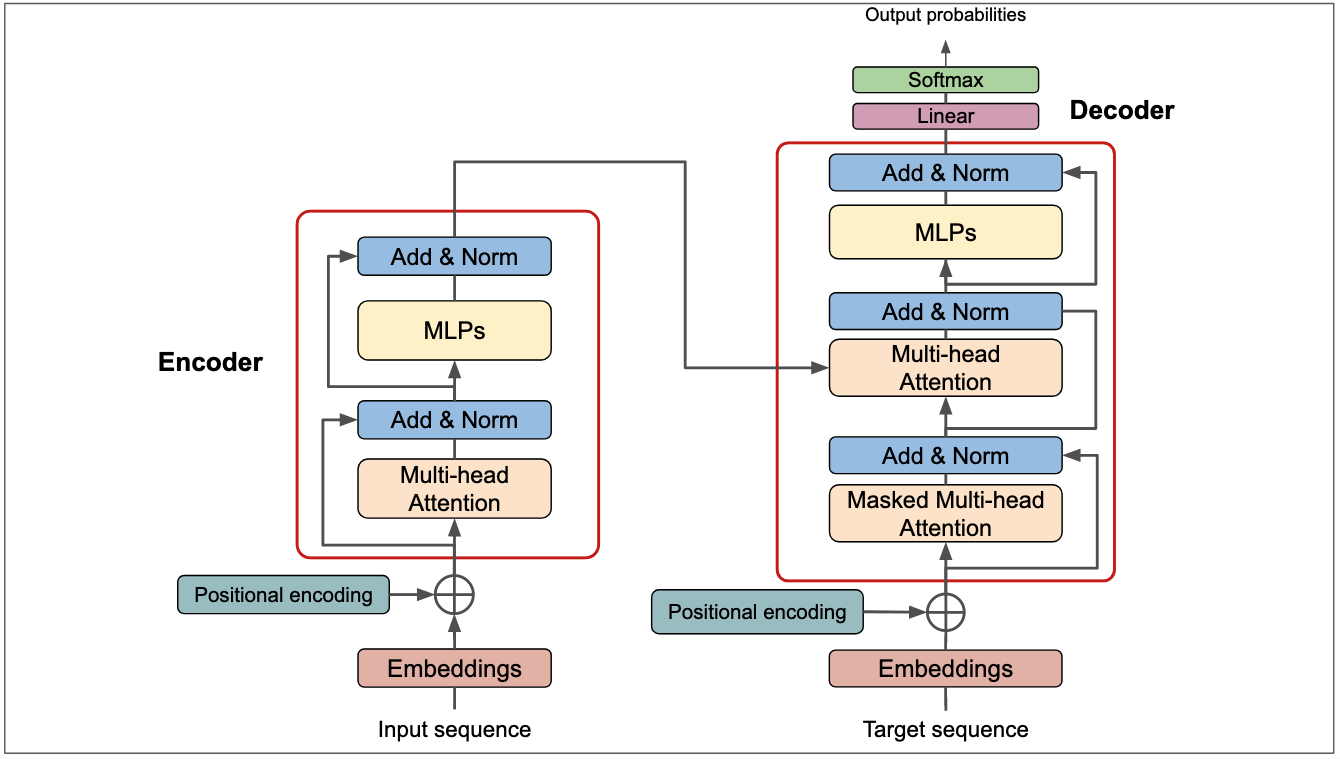
Let’s take a closer look at the fundamental components of a transformer model. Originally designed for sequence-to-sequence tasks like translation, the transformer architecture handles inputs where a sequence is fed into the model and an output sequence is generated in response. In this setup, the encoder processes the input to create a meaningful representation, which the decoder then references to generate the output.
Transformer Architecture. Source: https://deeprevision.github.io/posts/001-transformer/
The transformer model was later improved upon by the development of BERT (Bidirectional Encoder Representations from Transformers) by Devlin et al. BERT introduced a new approach to pre-training language models, using a combination of masked language modeling and next sentence prediction tasks to learn contextualized representations of words.
Current LLM Architectures
Today, the landscape of LLM architectures is diverse and rapidly evolving. Some of the most popular LLM architectures include:
- Transformer-XL: An extension of the transformer model, Transformer-XL uses a combination of self-attention mechanisms and recurrence to learn long-range dependencies in language.
- BERT: As mentioned earlier, BERT 2 is a pre-trained language model that uses a combination of masked language modeling and next sentence prediction tasks to learn contextualized representations of words.
- RoBERTa: A variant of BERT, RoBERTa uses a combination of masked language modeling and sentence ordering tasks to learn contextualized representations of words.
- XLNet 3: A generalized autoencoding framework, XLNet uses a combination of masked language modeling and permutation language modeling to learn contextualized representations of words.
- T5: A unified framework for text-to-text tasks, T5 uses a combination of masked language modeling and text-to-text generation tasks to learn contextualized representations of words.
LLM Architecture Variations
The transformer’s architecture has led to the development of three distinct variations: autoencoders, autoregressors, and sequence-to-sequence models. Each of these variations offers particular advantages and is tailored to specific use cases, making them well-suited for different LLM-based projects.
-
Autoencoders (Encoder only): Autoencoders utilize only the encoder part of the transformer architecture, discarding the decoder after pre-training. This approach allows the model to focus on learning a representation of the input data, making it ideal for tasks such as sentiment analysis and text classification.
Models like BERT and RoBERTa are good examples of autoencoders. They are trained using Masked Language Modeling (MLM), where specific tokens in the input sequence are masked, and the model is trained to predict these masked tokens. This training method enables the model to learn contextualized representations of words and phrases, which is essential for tasks that require understanding the nuances of language. -
Autoregressors (Decoder only): Autoregressors retain the decoder part of the transformer architecture while discarding the encoder after pre-training. This approach allows the model to focus on generating coherent and context-dependent text, making it ideal for tasks such as text generation and language translation.
Best known examples of autoregressors are GPT series and BLOOM. These models are trained using Causal Language Modeling, where the model predicts the next token in a sequence based on the preceding tokens. This training method enables the model to learn the patterns and structures of language, which is essential for tasks that require generating coherent and context-dependent text. -
Sequence-to-Sequence Models (Encoder - Decoder): Sequence-to-Sequence models include both encoder and decoder and are versatile in their training methods. This approach allows the model to learn both the input and output representations of the data, making it ideal for tasks such as language translation and text summarization.
Models like T5 and the BART family are examples of sequence-to-sequence models. They can be trained using techniques like span corruption and reconstruction, where portions of the input sequence are corrupted, and the model is trained to reconstruct the original sequence. This training method enables the model to learn the patterns and structures of language, which is essential for tasks that require generating coherent and context-dependent text.
Current Trends and Future Directions
The field of Large Language Model (LLM) training is rapidly evolving, with new techniques and approaches emeriging.
Advanced Pre-training Techniques
Pre-training remains a fundamental stage in LLM development, but recent advancements have significantly improved this process. The traditional approach to pre-training involves learning general language patterns and knowledge from diverse, large-scale text datasets using self-supervised learning methods such as masked language modeling and next token prediction.
However, a new multi-stage approach has been developed. This approach involves a core pre-training stage, followed by continued pre-training with high-quality data and context-lengthening with synthetic data for extended sequences. The key shift in this approach is prioritizing data quality over quantity, which has been shown to improve model quality and performance on downstream tasks.
Rise of Specialized Small Language Models (SLMs)
A notable trend in 2024 is the development of smaller, more efficient LLMs, known as Specialized Small Language Models (SLMs). Examples of SLMs include Microsoft’s PHI-2 , which uses strategic data selection, innovative scaling methods, and focused training on specific domains or tasks.
The benefits of SLMs include efficiency in computation and deployment on edge devices and resource-constrained environments, and comparable or superior performance to larger models in specific domains. This trend goes against the “bigger is better” paradigm in LLM development and opening new possibilities for AI deployment in various sectors.
Efficiency in LLMs
The field is seeing a push towards making LLMs more accessible, cost-effective and more environmental sustainable. Trends include the development of new APIs and open-source contributions that lower entry barriers, and research focus on maximizing performance and efficiency while reducing resource consumption.
Task or Industry-Specific AI
We see an increase in LLMs that are tailored to specific industries, such as finance, healthcare, and manufacturing. These models are developed with deep domain knowledge and specialized capabilities, and are designed to deliver highly specialized solutions that address unique industry challenges.
Ethical AI and Regulatory Considerations
As LLMs become more prevalent, ethical and regulatory aspects are gaining prominence. Key concerns include preventing misinformation and bias in model outputs, and ensuring responsible AI deployment across sectors.
Regulatory developments such as the approval of LLMs for public use in regions like China, and emerging governance frameworks for AI ethics and safety, are also being explored. The industry is recognizing the critical importance of addressing these ethical considerations and is increasing its focus on developing ethically aligned AI systems.
Conclusion
The landscape of large language models is rapidly changing, driven by enhancements in architecture design, pre-training techniques, and a the focus on efficiency and ethics. LLMs continue to redefine NLP. As we look ahead, the development of specialised, efficient, and ethically responsible models promises to address specific industry needs and contribute positively to society.
References
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N.,… & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008). ↩︎
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 3407-3413). ↩︎
-
Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R., & Le, Q. (2019). XLNet: Generalized autoregressive pretraining for language understanding. In Advances in neural information processing systems (pp. 5759-5769). ↩︎