GPU Acceleration for AI: Building Robust Platforms with AI Engineering

GPU Acceleration for AI: Addressing the Challenges and Building a Better Path Forward with AI Engineering
The excitement surrounding AI is undeniable. We’re seeing incredible advancements in areas like natural language processing and medical diagnostics. However, alongside these breakthroughs, we’re also facing some significant infrastructure hurdles. Getting these powerful AI models to run efficiently, particularly on GPUs, often involves more complexity than is immediately apparent.
GPUs, especially those from NVIDIA, have become the essential hardware for modern AI. But effectively utilizing them, particularly in the context of ephemeral training jobs or model fine-tuning, can present a unique set of challenges.
Navigating the Intricacies of NVIDIA Drivers
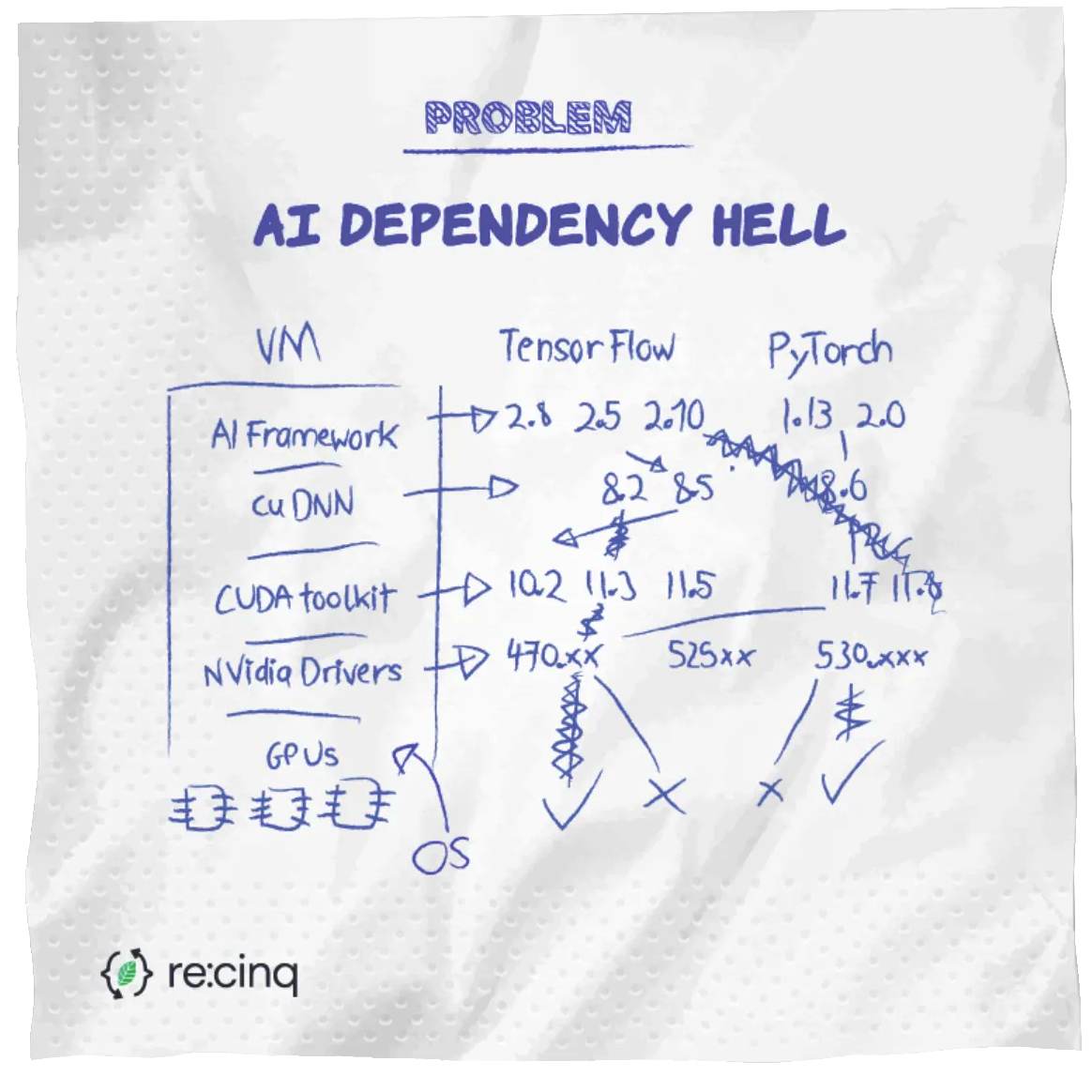
The process of installing and managing NVIDIA drivers can be, shall we say, involved. It requires careful attention to driver versions, CUDA toolkit compatibility, and the correct cuDNN library. Mismatches can lead to errors that are not always straightforward to identify, consuming valuable engineering time that could be spent on value-adding tasks. This process can feel somewhat at odds with the cutting-edge nature of the AI work itself.

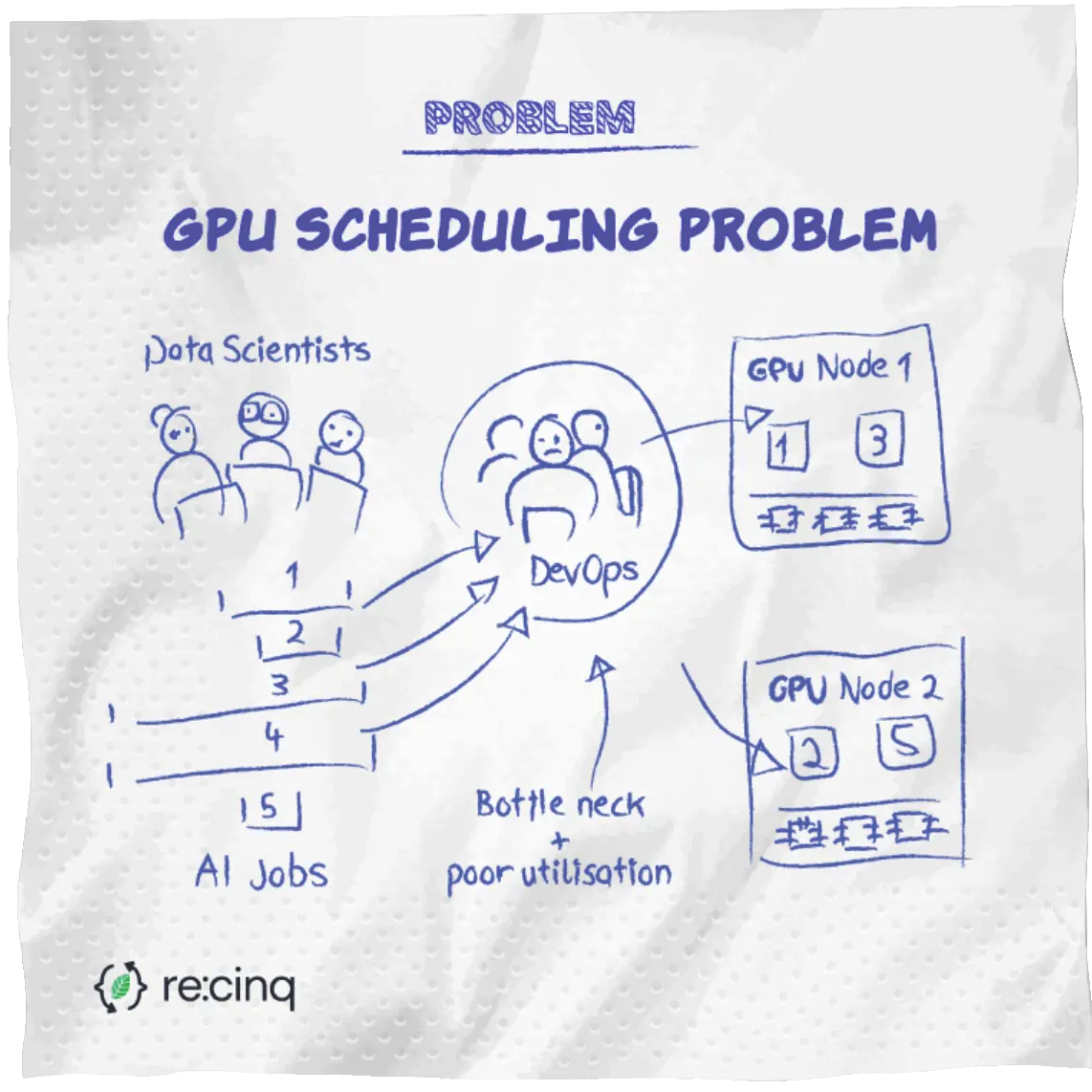
Even with the drivers successfully configured, there’s the matter of resource allocation. Ensuring your AI model gets the necessary GPU resources without impacting other processes or leaving valuable compute power underutilized requires careful planning.
Reproducibility is a key concern. In a field striving for scientific rigor, consistent results across different environments are key. Yet, subtle variations in driver versions, CUDA installations, or even OS updates can sometimes lead to unexpected discrepancies. This adds complexity, particularly when building robust, short-lived environments for ad-hoc model training.
Kubernetes and Containers: A Promising Approach
So, how do we address these challenges? Containerization and orchestration, particularly with Kubernetes, offer a compelling solution.
The core strategy revolves around encapsulation and abstraction. By packaging your model, along with its specific dependencies like the correct CUDA and cuDNN versions, into a Docker container, you create a self-contained, portable unit of deployment. This is then managed by a K8s cluster, which itself is running on a virtual machine that has been carefully set up for GPU passthrough.
This does require some initial setup. A platform engineer will need to configure the VM, ensure proper IOMMU settings, and verify that the K8s cluster has access to the underlying GPU hardware. And, yes, this is where the driver setup must also be handled with care.
However, once this foundation is established, the benefits are significant. Data scientists are largely insulated from the complexities of the underlying infrastructure. They simply submit their containerized model as a job to the K8s cluster, and Kubernetes handles the details of resource allocation, scheduling, and execution.
Platform Engineering: A Key Discipline for the AI Age
This exemplifies the principles of platform engineering. We’re creating a reusable, self-service platform that simplifies infrastructure management, allowing developers to concentrate on higher-level tasks. The platform engineer has performed the necessary groundwork, and from that point on, the data scientist can focus on their core expertise.
AI Engineering: Taking it a Step Further
While platform engineering provides the foundation, AI Engineering builds upon it to create a truly streamlined and efficient AI development lifecycle. As defined by re:cinq (https://blog.re-cinq.com/posts/ai-engineering/ ), AI Engineering focuses on the application of robust engineering principles to the entire AI lifecycle. This includes not just infrastructure, but also data management, model development, deployment, and monitoring.
In the context of GPU acceleration, AI Engineering means:
- Automating the complexities: Going beyond simply containerizing and orchestrating. AI Engineering emphasizes automation of the entire GPU provisioning and management process. This might involve tools for automatically scaling GPU resources based on workload demands, or systems for optimizing driver and dependency management.
- Standardizing workflows: Creating standardized, repeatable processes for model training and deployment on GPUs. This includes defining clear guidelines for containerization, dependency management, and resource allocation, ensuring consistency and reproducibility across projects.
- Integrating MLOps practices: Implementing MLOps principles to monitor the performance of models running on GPUs, track resource utilization, and automate retraining and redeployment. This ensures that AI systems are not only performant but also reliable and maintainable.
- Focusing on the entire lifecycle: AI Engineering considers the complete AI lifecycle, from data ingestion and preprocessing to model training, deployment, and monitoring. This holistic view allows for optimization across the entire process, including efficient GPU utilization at each stage.
By incorporating AI Engineering principles, we move beyond simply managing GPUs to truly optimizing their use for AI workloads, enabling organizations to focus on what matters: delivering value to their customers. This means data scientists can focus on model development and innovation, while AI Engineers build and maintain the robust, scalable, and efficient systems that power them.
Our Work with Exoscale: Empowering AI Innovation
We’re proud to be working with Exoscale, a leading provider of IaaS, to help them empower their customers in the AI space. Exoscale offers GPU resources as part of their infrastructure, and we’re collaborating with them to develop an extension of their Command Line Interface (CLI) designed to simplify the use of these GPU resources for AI model training, particularly for short-running jobs.
Our goal is to lower the barrier to entry for AI customers using Exoscale’s platform. The CLI extension will provide users with an easy way to access and utilize available GPUs. Key features of this project include:
- Automated Image Creation: Leveraging Packer and containers to automate the creation of custom machine images, streamlining deployment processes.
- Simplified Model Training: Building model training functionalities that abstract away the underlying infrastructure complexities, allowing users to focus on their models.
- Flexible Model Provisioning: Offering multiple integration options, including direct support for models hosted on Hugging Face.
This project with Exoscale exemplifies our commitment to AI Engineering principles. By automating key processes, standardizing workflows, and focusing on the entire AI lifecycle, we are helping Exoscale build a platform that empowers their customers to innovate faster and more efficiently.

Looking Ahead: The Importance of Robust Platforms and AI Engineering
The challenges surrounding GPU utilization for AI underscore a broader trend: the growing need for robust, well-engineered platforms and the application of sound engineering principles to the AI lifecycle.
As AI continues to advance our technological landscape, effective management of the underlying infrastructure and the application of AI Engineering best practices will become even more critical. The container/K8s/VM approach, combined with a focus on AI Engineering principles, provides a valuable blueprint for the future. It suggests a path where platform engineering and AI Engineering play a central role, empowering AI practitioners to push the boundaries of what’s possible, without getting bogged down in the intricacies of driver versions and kernel modules, especially when working in short-lived environments for quick experiments and prototyping. It’s a future focused on progress and innovation, and that’s a direction we should all be striving towards.
Stay Updated & Let’s Connect!
Technology is Evolving—Are You Keeping Up?
Let's explore how to stay ahead and keep you updated with our latest insights.