Llama and DeepSeek with LibreChat for Conversational AI

This tutorial guides you through deploying Llama and DeepSeek using SGLang, a powerful library for efficient LLM serving and integrate with LibreChat for seamless conversations. We’ll deploy two popular models: deepseek-ai/deepseek-llm-7b-chat and meta-llama/Llama-3.1-8B-Instruct. The process is adaptable for any model supported by SGLang
. For detailed model information, refer to the supported models section
.
Prerequisites
Before starting, you’ll need:
- Hugging Face Account & Access Token:
- A Hugging Face account.
- A generated Hugging Face Access Token with READ permissions. Create one here . This token is essential for downloading model weights securely.
- DataCrunch Account:
- A DataCrunch AI cloud account.
- A DataCrunch project ready for deployment.
- Compute Resources:
- Ensure your DataCrunch project has sufficient compute resources. We recommend at least a General Compute instance with 24GB VRAM. Larger models may require more VRAM.
Understanding Model Weights and Hugging Face
SGLang seamlessly fetches model weights directly from the Hugging Face Model Hub. This tutorial uses:
deepseek-ai/deepseek-llm-7b-chatmeta-llama/Llama-3.1-8B-Instruct
Important:
- Usage Policy: Many models, including those from Meta, require you to accept their usage policy on their Hugging Face model page before you can download them. Visit the model pages and ensure you’ve accepted the policy if prompted.
- Hugging Face Access Token: Keep your Hugging Face Access Token secure. It’s like a password for accessing models.
Deployment Steps on DataCrunch
-
Log in to DataCrunch: Access your DataCrunch cloud dashboard.
-
Navigate to your Project: Open an existing project or create a new one.
-
Create New Deployment:
- Go to Containers -> New deployment.
- Name: Give your deployment a descriptive name (e.g.,
deepseek-sglang). - Compute Type: Select an appropriate type (General Compute with at least 24GB VRAM recommended).
-
Container Image Configuration:
- Container Image: Use the official SGLang Docker image:
docker.io/lmsysorg/sglang:v0.2.13-cu124(or choose your preferred version from SGLang Docker Hub ). - Public Location: Keep “Public location” toggled ON unless you’re using a private container registry. For production or to avoid potential rate limits during development, consider using a private registry.
- Container Image: Use the official SGLang Docker image:
-
Port Configuration:
- Exposed HTTP port:
30000 - Healthcheck port:
30000 - Healthcheck path:
/health
- Exposed HTTP port:
-
Start Command Configuration:
- Enable “Start Command”.
- CMD: Enter the following command. This command starts the SGLang server, specifying the model, host, and port:
python3 -m sglang.launch_server --model-path deepseek-ai/deepseek-llm-7b-chat --host 0.0.0.0 --port 30000- Explanation:
python3 -m sglang.launch_server: Executes the SGLang server script.--model-path deepseek-ai/deepseek-llm-7b-chat: Specifies the Hugging Face model to load. To deploy Llama 3, you would change this tometa-llama/Llama-3.1-8B-Instruct.--host 0.0.0.0: Makes the server accessible from outside the container.--port 30000: Sets the server port to 30000, matching the exposed port.
-
Environment Variables:
- Add an environment variable named
HF_TOKEN. - Value: Paste your Hugging Face User Access Token here.
- Add an environment variable named
-
Deploy! Click “Deploy container”.
DataCrunch will now pull the SGLang image, download the model weights from Hugging Face, and start the SGLang container. This process can take several minutes depending on the model size, so please be patient.
Monitoring Deployment:
- Logs Tab: Check the “Logs” tab of your deployment in DataCrunch. This will show the progress. Look for messages indicating successful model download and server startup. If errors occur, the logs are your primary source for troubleshooting.
Accessing Your Deployed Endpoint
- Generate API Key:
- Navigate to Keys -> Inference API Keys.
- Click “Create new key” to generate an API key for accessing your deployment.
- Find Endpoint URL:
- Go to Containers API section (usually found on the main Containers page or within your deployment details).
- The base endpoint URL will be listed there. It typically looks like
https://containers.datacrunch.io/<YOUR-DEPLOYMENT-NAME>/.
Testing with curl
Verify your deployment is working using a get_model_info request. This checks if the SGLang server is running and serving the correct model information.
Open your terminal and run the following curl command, replacing placeholders with your actual values:
curl -X GET https://<YOUR_CONTAINERS_API_URL>/get_model_info \
--header 'Authorization: Bearer <YOUR_INFERENCE_API_KEY>' \
--header 'Content-Type: application/json'
Expected Successful Response:
{
"model_path": "deepseek-ai/deepseek-llm-7b-chat",
"tokenizer_path": "deepseek-ai/deepseek-llm-7b-chat",
"is_generation": true
}
If you see this response, your SGLang endpoint is deployed and working correctly!
Deploying Different Models (e.g., Llama 3)
To deploy a different SGLang-compatible model, simply repeat steps 3-8 in the “Deployment Steps on DataCrunch” section, changing only the --model-path in the Start Command.
For example, to deploy Llama 3, use:
python3 -m sglang.launch_server --model-path meta-llama/Llama-3.1-8B-Instruct --host 0.0.0.0 --port 30000
Integrating with LibreChat Locally (Podman Example)
Let’s connect LibreChat, a user-friendly chat interface. We’ll use a local Podman setup for this example. Docker Compose (or Podman Compose) is the easiest way to run LibreChat.
Prerequisites:
- Git (Install Git )
- Podman & Podman Compose (Install Podman and Podman Compose on Mac )
Installation Steps:
- Clone LibreChat Repository:
git clone https://github.com/danny-avila/LibreChat.git
- Navigate to LibreChat Directory:
cd LibreChat
- Create Configuration Files:
cp .env.example .env
cp librechat.example.yaml librechat.yaml
-
Configure
librechat.yamlfor DataCrunch SGLang Endpoint:Open
librechat.yamland add the followingcustomsection. Crucially, ensurebaseURLpoints to your DataCrunch endpoint’s base URL followed by/v1:
custom:
- name: "DeepSeek" # Name as it appears in LibreChat
apiKey: "<YOUR_INFERENCE_API_KEY>" # Your DataCrunch Inference API Key
baseURL: "https://<YOUR_CONTAINERS_API_URL>/v1/chat/completions # **Corrected baseURL for SGLang**
models:
default: [
"deepseek-llm-7b-chat", # Model name as used in SGLang/Hugging Face
]
fetch: false
titleConvo: true
titleModel: "current_model"
summarize: false
summaryModel: "current_model"
forcePrompt: false
modelDisplayLabel: "DeepSeek on DataCrunch" # Display label in LibreChat
- name: "Llama 3" # Another custom model configuration
apiKey: "<YOUR_INFERENCE_API_KEY>"
baseURL: "https://<YOUR_CONTAINERS_API_URL>/v1/chat/completions" # **Correct baseURL for SGLang**
models:
default: [
"Llama-3.1-8B-Instruct", # Model name as used in SGLang/Hugging Face
]
fetch: false
titleConvo: true
titleModel: "current_model"
summarize: false
summaryModel: "current_model"
forcePrompt: false
modelDisplayLabel: "Llama 3 on DataCrunch" # Display label in LibreChat
-
Modify
apiservice volumes indocker-compose.yaml:In the
docker-compose.yaml, find theapiservice definition. Within theapiservice, locate thevolumessection and extend it to include a bind mount for yourlibrechat.yamlfile. It should look like this (add the- type: bindsection):
services:
api:
# ... other api service configurations ...s
volumes:
# ... existing volumes ...
- type: bind
source: ./librechat.yaml # Path to your librechat.yaml file
target: /app/librechat.yaml # Path inside the container where LibreChat expects it
# ... more volumes ...
-
Remove
extra_hostsfor Podman (if using Podman):If you are using Podman (especially on macOS or Windows), find the
apiservice in your compose file and remove theextra_hostssection entirely.extra_hostsis Docker Desktop specific and not needed with Podman.services: api: # ... other api service configurations ... # REMOVE THIS ENTIRE SECTION IF USING PODMAN: # extra_hosts: # - 'host.docker.internal:host-gateway' # ... rest of api service configurations ... -
Start LibreChat with Podman Compose:
podman compose up -d
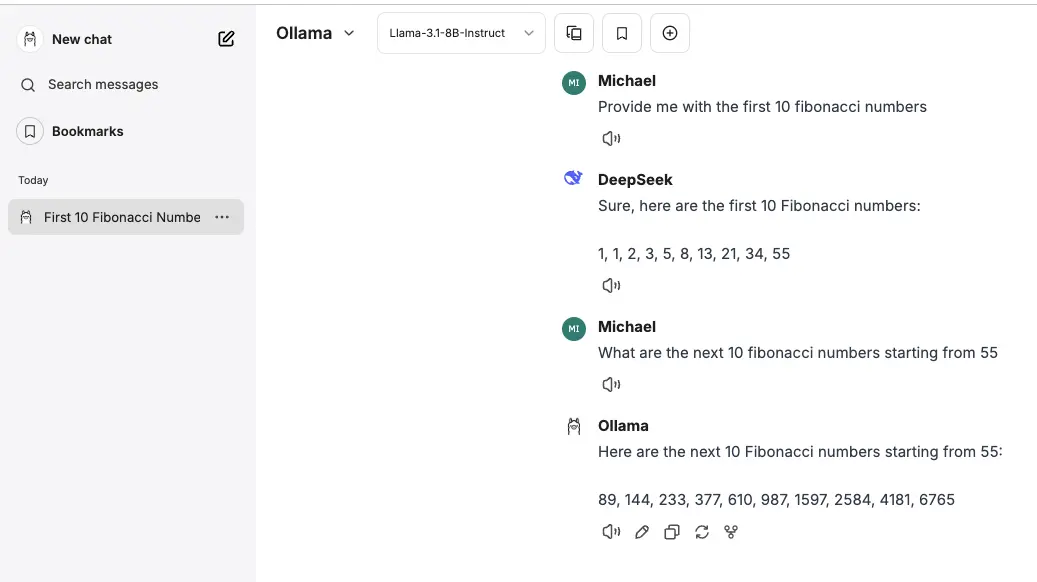
🎉 Access LibreChat!
Open your web browser and go to http://localhost:3080/. You should now see the LibreChat interface. In the model selection dropdown, you will find “DeepSeek” and “Llama”. Select one and start chatting!
Enjoy interacting with your deployed LLMs through LibreChat!
Troubleshooting Tips:
- Deployment Stuck/Errors: Check the DataCrunch deployment “Logs” tab for error messages. Common issues include:
- Hugging Face Token Issues: Double-check your
HF_TOKENenvironment variable is correctly set and valid. - Compute Resource Limits: Ensure your DataCrunch project has sufficient VRAM. Out-of-memory errors will be visible in the logs. Try a larger Compute Type.
- Model Policy Acceptance: Verify you’ve accepted the usage policy on the model’s Hugging Face page.
- Container Image Errors: Double-check the SGLang Docker image name.
- Hugging Face Token Issues: Double-check your
- LibreChat Connection Issues:
- Incorrect
baseURLinlibrechat.yaml: Double-check thatbaseURLishttps://<YOUR_CONTAINERS_API_URL>/v1/chat/completions. - API Key Errors: Ensure your DataCrunch Inference API Key is correctly placed in
librechat.yaml. - LibreChat Logs: Examine the logs of the LibreChat
apicontainer (usingpodman logs -f <api_container_name>) for connection errors.
- Incorrect
- Slow Responses: LLM inference can be slow, especially for larger models. Response times depend on the model size, compute resources, and network latency.
By following these steps, you’ve successfully deployed LLMs using SGLang on DataCrunch and connected them to LibreChat, creating a powerful and private AI chat environment!
Ready to Take the Next Step and Build Your Own LLM?
This tutorial showed you how to deploy pre-trained LLMs using SGLang and DataCrunch manually. But what if you want to go further and create a custom LLM tailored to your specific needs? DataCrunch provides the robust infrastructure and scalable compute resources necessary to train your own Large Language Models from scratch, or fine-tune existing models with your proprietary data.
If you’re interested in exploring the possibilities of building and training your own LLMs, we’re here to help! Reach out to our team today to discuss your project, explore available resources, and discover how DataCrunch can empower you to create cutting-edge AI solutions. Let us help you bring your unique LLM vision to life!